
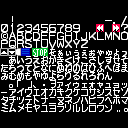
I just took a quick look at this game and here are the cool stuffs. The games has 2 fonts, an 8x8 one with numbers, symbols, upper case and 8x8 kanji (I think), and a 16x16 one. The text for the introduction starts at $4dc49. The date 1921 is stored in plain ascii. So I brutally wrote some stupid text in upper case and voilà!

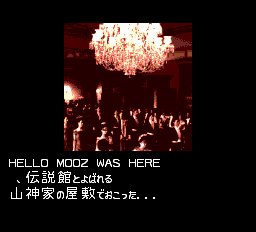
I identified 2 special chars : $fc for newline $fb which indicates that the next byte is one of the 16x16 symbol.
About the code: I made a quick read and it seems that it comes in 2 part. First the text is read from ROM and put in an array in BSS ($9bb6 to 9bc5).
Code: Select all
9bb6: cly
clx
9bb8: lda ($06),y
sta $2220,x
beq $9bc5
inx
jsr $9c74
bra $9bb8
rtsCode: Select all
9d84: lda $10
sta $0002
lda $11
sta $0003
lda ($2a),y
cmp #$de
beq $9d98
cmp #$df
bne $9da9
9d98: inyCode: Select all
9b13: lda ($06),y
cmp #$fe
beq $9b20
sta $0e
9b1b: jsr $9c74
bra $9b13
9b20: lda $0e
cmp $33dd
bne $9b1b
; ...Code: Select all
ae55: lda #$01
sta $33dd
lda #$05
clx
jsr $9f1b
; ...Code: Select all
8012: ldx #$02
stx $33dd
jsr $80f6
; ... 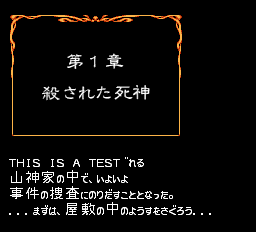
The string table (or what's close to it) is getting closer!
Next items on the todo list:
- String tables.
- Font data.
- Extract script.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}